CNN model for Mandarin tone classfication
今日总结
tensorflow is hard as hell
今日试图 复现 deep learning method for tone classficiation ToneNet (https://github.com/saber5433/ToneNet)。
现阶段 单音节的 声调识别已经相当完善了,主要有论文
Tonenet 发表于 interspeech 2019 @Gaoqing
在单音节的标准发音上,可以达到百分之99以上的识别率
主要思路是使用多种参数,例如pitch-related, spectragom, mel-spectragom.
作者使用了CASS语料库,即中文标准音节发音语料库,因为商业性(费用约2000元)暂时搁置,此类语料库也有Tone Perfect dataset from Michigan State University (https://tone.lib.msu.edu/).
The Tone Perfect collection includes the full catalog of monosyllabic sounds in Mandarin Chinese (410 in total) in all four tones (410 x 4 = 1,640). Spoken by six native Mandarin speakers (three female and three male), the collection is comprised of 9,860 audio files (6 sets of 1,640). 如图所示为该语料库所提供的标准范例。
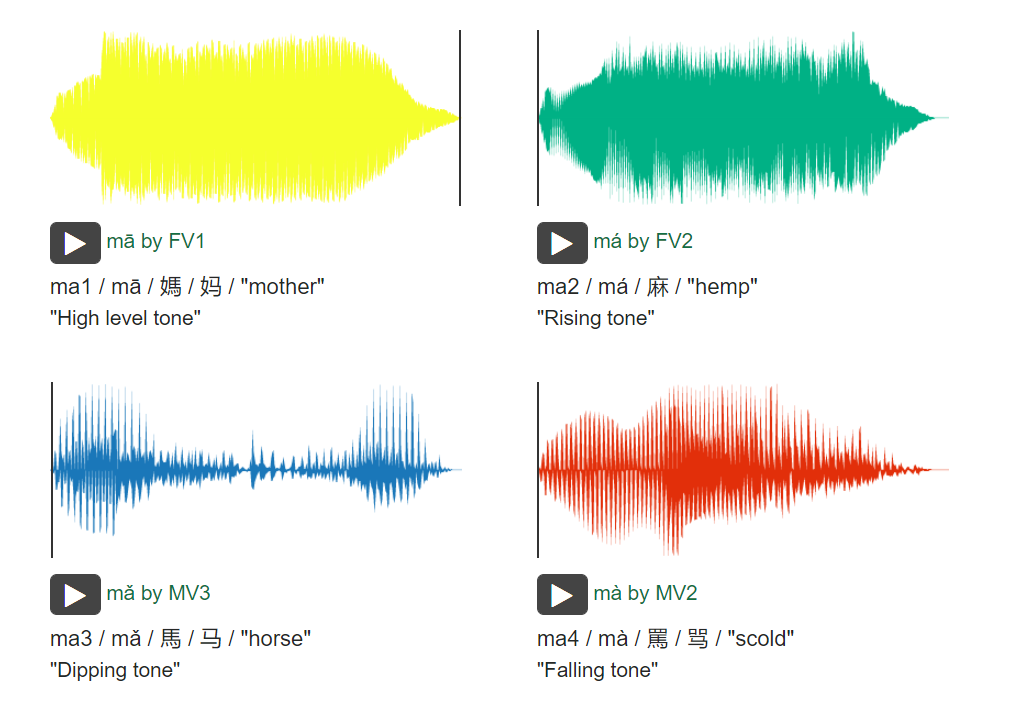
使用该数据库需要先填写申请表,已经提交,但尚未有工作人员回应,继续等待中。
故而先行使使用BLCU-SAIT的小部分语料库中的单音节,总计约10000条不同的语音片段,来自3男3女,每位发音人产出1520个不同声调的单音节。 数据量和前人的实验研究向符合。
- 使用python可以较为方便的提取不同层级的声学特征
Note 因为使用深度学习进行的序列建模中,输入的参数维度是需要保持一致,但音频本身的时长不一,所以大多数的研究方法是进行padding,即补零到最长的音频时长,因为录音细节的问题,部分音节的时长过长,约3-5s 增加了计算量,故而先行对数据进行trim (即 去除首 尾 部分的静音段 )
# Load some audio
y, sr = librosa.load(librosa.ex('choice'))
# Trim the beginning and ending silence
yt, index = librosa.effects.trim(y)
# 可选参数包括:
# top_dbnumber > 0 The threshold (in decibels) below reference to consider silence !重要
# Print the durations
print(librosa.get_duration(y), librosa.get_duration(yt))
25.025986394557822 25.007891156462584
import librosa
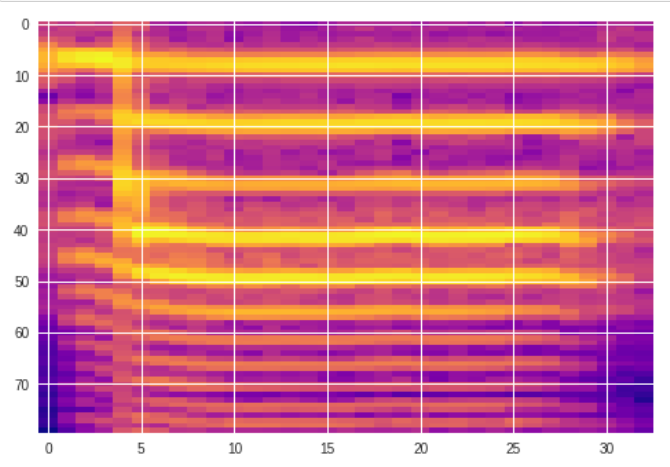
# 提取 频谱特征;
mel1 = librosa.feature.melspectrogram(audio1, sr=sample_rate1, n_fft=1024, hop_length=512, n_mels=80, fmin=75, fmax=3700)
plt.imshow(np.log10(mel1 + 1e-10), aspect='auto', cmap=cm.plasma)
plt.show()
print(mel1.shape)
import librosa
# 提取 mfcc
mfcc = librosa.feature.mfcc(y=audio1, sr=sample_rate1, n_mfcc=60)
plt.imshow(mfcc, aspect='auto', cmap=cm.viridis)
plt.show()
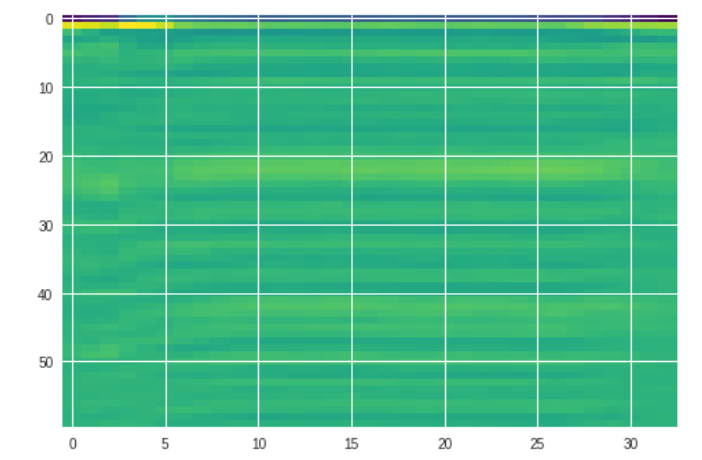 tone1
tone1
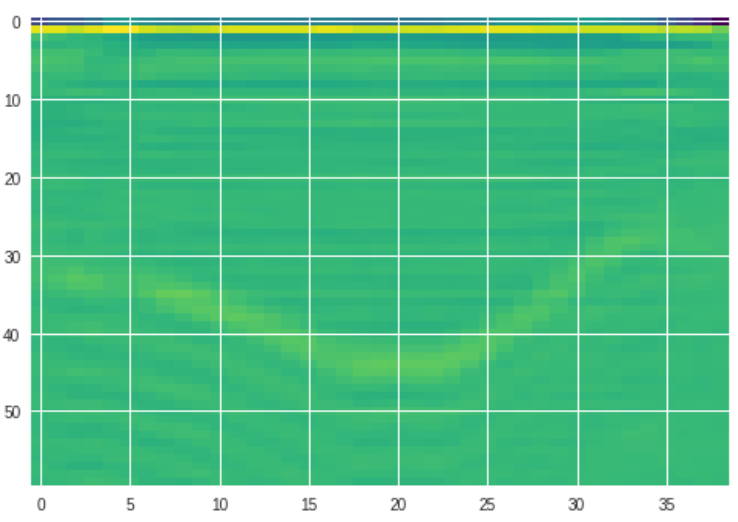 tone3
tone3
# 使用librosa自带的框架提取 音高 TODO 可变化
# e.g. pyworld / cnn pitch
pitch, mag = librosa.core.piptrack(audio1, sr=sample_rate1, n_fft=512)
plt.imshow(pitch, aspect='auto')
plt.ylim([20,100])
plt.show()
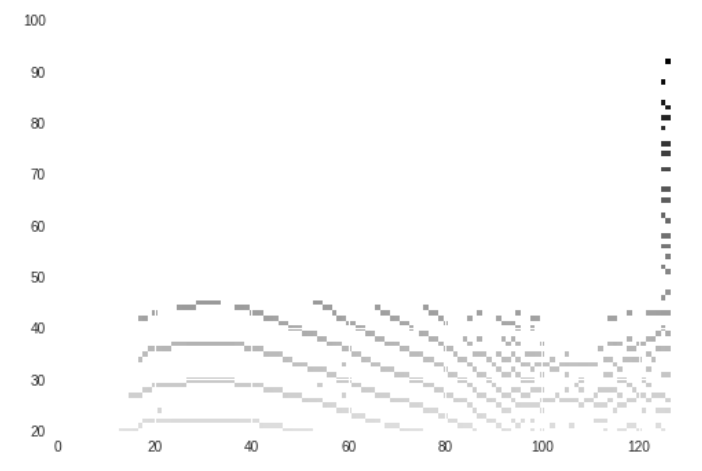
如图可见为不同方法是声调表征,从直观视觉,mfcc更贴合实际的声调轮廓。
数据准备
# import some necessary packages
import tensorflow as tf
import keras
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D, BatchNormalization
from sklearn.model_selection import train_test_split
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.utils import np_utils
from keras.utils import to_categorical
import numpy as np
import matplotlib
import math
import os
# 定义模型
def get_cnn_model(input_shape, num_classes):
model = Sequential()
model.add(Conv2D(32, kernel_size=(2, 2), activation='relu', input_shape=input_shape))
model.add(BatchNormalization())
model.add(Conv2D(48, kernel_size=(2, 2), activation='relu'))
model.add(BatchNormalization())
model.add(Conv2D(120, kernel_size=(2, 2), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
return model
为了更方便的理解模型,可使用 model.summary ( After training.)
数据预处理中,使用liborsa提取mfcc参数,此处提取60维mfcc参数,对全部语音进行首尾静音段的切除,最后padding到150帧,最后将数据转换为np.array并保存。最终训练数据 维度为(9199,60,150,1)
def wav2mfcc(file_path, max_pad):
# 使用librosa读取音频时,可能遇到soundfile的依赖错误,此时可以选择重新安装soundfile包,或直接使用soundfile进行读取,读取后的音频 audio 和 sample rate 和 librosa无差异。
#audio, sample_rate = librosa.core.load(file_path)
mfcc = librosa.feature.mfcc(y=audio, sr=sample_rate, n_mfcc=60)
pad_width = max_pad - mfcc.shape[1]
mfcc = np.pad(mfcc, pad_width=((0, 0), (0, pad_width)), mode='constant')
return mfcc
对 数据标签进行one-hot编码,即 将1 2 3 4 的离散数值,转换为 [0,0,0,0,1] [0,0,0,1,0] [0,0,1,0,0] [0,1,0,0,] 可以使用 keras自带的 to_categorical
from keras.utils import to_categorical
labels = to_categorical(labels, num_classes=None)
print(labels.shape)
训练和测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
model = get_cnn_model(input_shape, classes)
history = model.fit(X_train, y_train, batch_size=20, epochs=15, verbose=1, validation_split=0.2, class_weight=class_weights)
最终结果 :
模型
测试集上的混淆矩阵
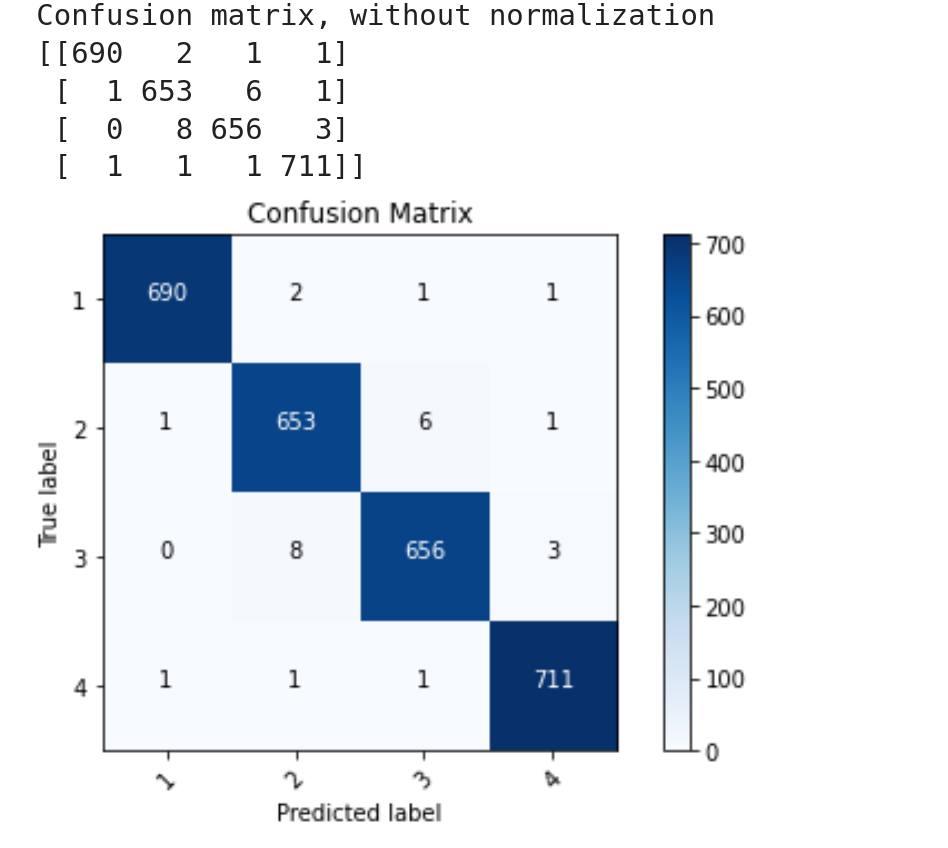
基本上训练的很好,但是可能有点过拟合了哈,不知道集外的数据如何。
试图使用gradio制作一个可交互app
Generate an easy-to-use demo for your ML model or function with only a few lines of code.
